library(tidyverse)5 Exploration von kategorialen Daten
- Den Pipe-Operator
%>%nutzen - Kategoriale Variablen in Faktoren umwandeln
- Kategoriale Variablen darstellen
- Neue Variablen mit
mutate()erstellen - Häufigkeits- und Kontingenztabellen erstellen
5.1 Mobilität in Europa
Wir nutzen erneut den Datensatz aus der ersten Sitzung der Vorlesung. Zunächst laden wir wie immer die nötigen Bibliotheken.
Das Einlesen eines Datensatzes aus einer Textdatei haben Sie ja bereits im letzten Kapitel gelernt.
car_numbers <- read_delim(file = 'Daten/autos_2024-10-14.csv', delim = ';')5.1.1 Kategoriale Variablen als Faktoren
Wir sehen uns das tibble etwas genauer an.
car_numbersKategorische Variablen werden als Text (character) eingelesen. Das bedeutet, dass wir R nicht (so leicht) fragen können, welche verschiedenen Merkmalsausprägungen die Variable enthält. Zur Erinnerung: Merkmalsausprägungen sind die theoretisch möglichen Werte, die eine Variable annehmen kann. Merkmalswert ist dann der tatsächlich beobachtete Wert (die Beobachtung), den die Variable angenommen hat.
Eine bessere Klasse für eine kategoriale Variable ist ein Faktor (factor). Bei einem Faktor werden die unterschiedlichen Merkmalsausprägungen (levels) explizit gespeichert. Wir wandeln daher die Text-Variable geo in einen Faktor um.
car_numbers <- car_numbers %>%
mutate(geo_factor = as_factor(geo))Das Zeichen %>% heißt Pipe-Operator. Man spricht ihn als und dann aus. Die Funktion des Pipe-Operators ist ein Weitergeben oder ein Übergeben des Objekts auf der linken Seite des Pipe-Operators (also car_numbers) an die erste Stelle der Funktion in der neuen Zeile (bzw. rechts vom Pipe-Operator, also an die Funktion mutate()). Das bedeutet, dass man den Code oben auch wie folgt schreiben könnte:
car_numbers_test <- mutate(.data = car_numbers, geo_factor = as_factor(geo))Es kommt dasgleiche raus:
car_numberscar_numbers_testDas ist aber viel unübersichtlicher als mit dem Pipe-Operator. Da dieser den Code so schön strukturiert, wird er häufig verwendet und ist ein fester Bestandteil von tidyverse. Seit der R-Version 4.1.0 gibt es einen weiteren Pipe-Operator |>. Er ist Teil von R base, also der Grundausstattung in R, und man braucht kein Paket zu laden, um diesen Pipe-Operator zu benutzten. Allerdings ist der Pipe-Operator %>% aus tidyverse flexibler. Daher arbeiten wir mit diesem.
Die Funktion mutate() kann neue Variablen in einem Datensatz erstellen, verändern oder löschen. In unserem Fall erstellen wir eine neue Variable, die wir geo_factor nennen. Die Funktion as_factor() wandelt (konvertiert) die Text-Variable geo in einen Faktor.
Den Code car_numbers %>% mutate(geo_factor = as_factor(geo)) kann man also aussprechen als:
- Nimm den Datensatz
car_numbersund dann - erstelle darin eine neue Variable
geo_factor, in der die Variablegeoals Faktor abgespeichert wird.
Den Pipe-Operator erhält man mit der Tastenkombination Str+Shift+M.
Die Funktion mutate() fügt neue Variablen am Ende des Datensatzes ein:
car_numbersNun können wir R auch fragen, welche verschiedenen Merkmalsausprägungen (levels) diese Variable enthält:
levels(car_numbers$geo_factor) [1] "Albania" "Austria" "Belgium"
[4] "Bosnia and Herzegovina" "Bulgaria" "Croatia"
[7] "Cyprus" "Czechia" "Denmark"
[10] "Estonia" "Finland" "France"
[13] "Georgia" "Germany" "Greece"
[16] "Hungary" "Iceland" "Ireland"
[19] "Italy" "Kosovo*" "Latvia"
[22] "Liechtenstein" "Lithuania" "Luxembourg"
[25] "Malta" "Moldova" "Montenegro"
[28] "Netherlands" "North Macedonia" "Norway"
[31] "Poland" "Portugal" "Romania"
[34] "Serbia" "Slovakia" "Slovenia"
[37] "Spain" "Sweden" "Switzerland"
[40] "Türkiye" "United Kingdom" Die einzelnen Merkmalsausprägungen sind die verschiedenen Länder. Der Datensatz enthält 41 unterschiedliche Länder.
5.1.2 Balkendiagramm mit geom_col()
Wir möchten die Daten als Balkendiagramm darstellen. Das Ziel ist eine ähnliche Darstellung, wie in der Vorlesung.
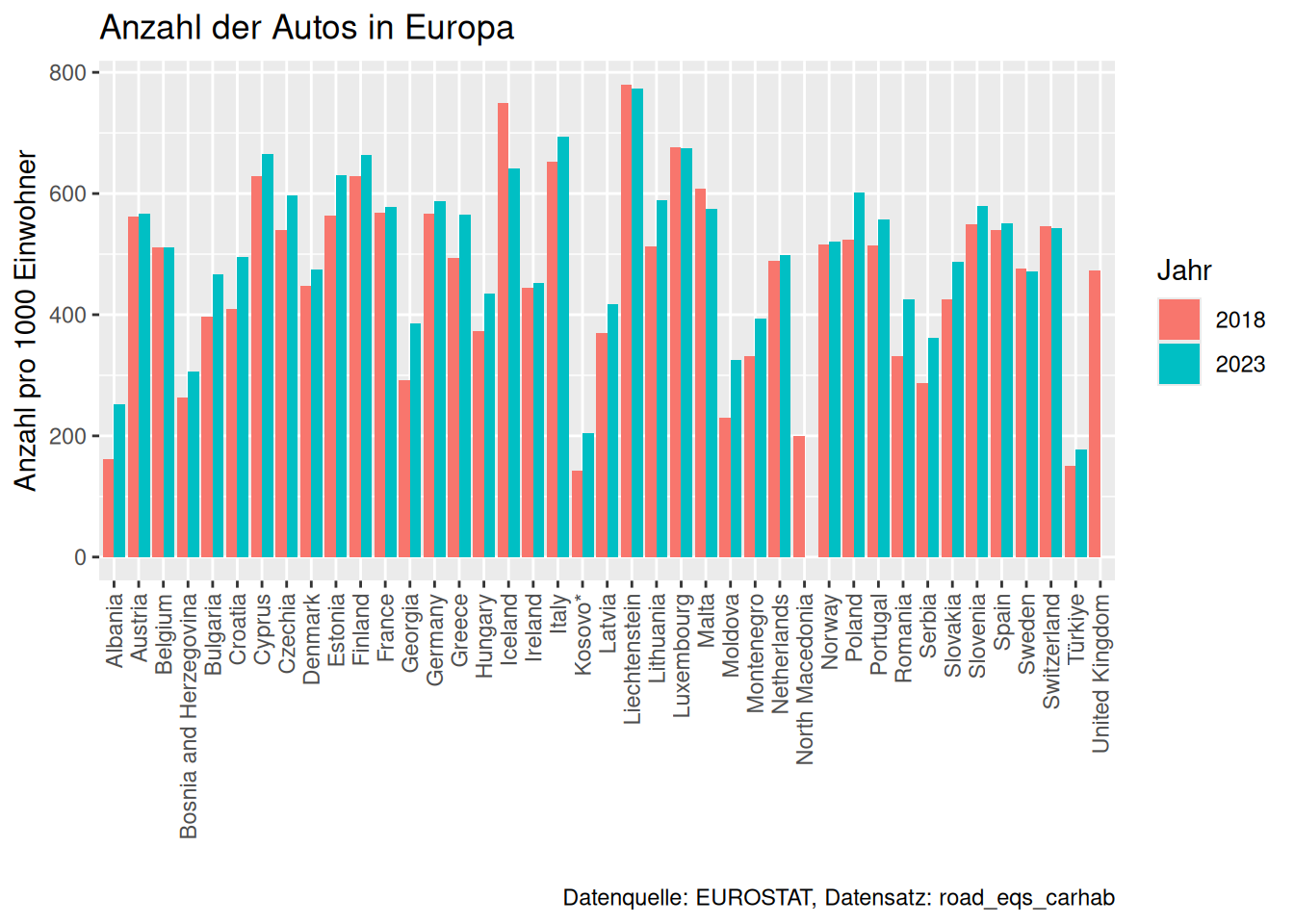
Dafür müssen wir zuerst eine neue Variable erstellen, die wir zum Einfärben der Jahre nutzen können. Dazu benötigen wir eine zusätzliche Bibliothek, die uns den Umgang mit Datum und Uhrzeit erleichtert. Sie heißt lubridate.
library(lubridate)Nun nutzen wir die Funktion year() aus lubridate, um aus der Variablen TIME_PERIOD nur das Jahr zu extrahieren. Wir erstellen dazu mit mutate() wieder eine neue Variable, die wir time_year nennen.
car_numbers <- car_numbers %>%
mutate(time_year = year(TIME_PERIOD))Auch diese Variable wir an das Ende des Datensatzes car_numbers gestellt.
car_numbersEine Variable zum Einfärben mit zwei verschiedenen Farben (je Jahr eine andere Farbe) muss kategorial sein. Die Variable time_year ist aber numerisch. Daher nutzen wir mutate(), um time_year in einen Faktor zu verwandeln.
car_numbers <- car_numbers %>%
mutate(time_year = as_factor(time_year))In diesem Fall erstellt mutate() keine neue Variable, sondern überschreibt (verändert) die vorhandene Variable time_year. Das ist möglich und gängige Praxis in R. Jetzt ist time_year ein Faktor, was man auch in der Darstellung des tibble sehen kann.
car_numbersNun geht es an die Darstellung. Im Kapitel 3 haben Sie das geom_bar() kennengelernt. Es kann die Anzahl der Einträge in einer Variablen auszählen und diese als Balkendiagramm darstellen. Das möchten wir aber in unserem Fall nicht. Wir wollen die Anzahl der Autos darstellen, die in der Variablen value enthalten ist. In anderen Worten, wir wollen die Merkmalswerte (Beobachtungen) selbst und und nicht deren Anzahl (counts) darstellen. Das ist die Aufgabe des geom_col() (col steht für columns, also Säulen/Balken).
ggplot(data = car_numbers, mapping = aes(x = geo, y = values, fill = time_year)) +
geom_col()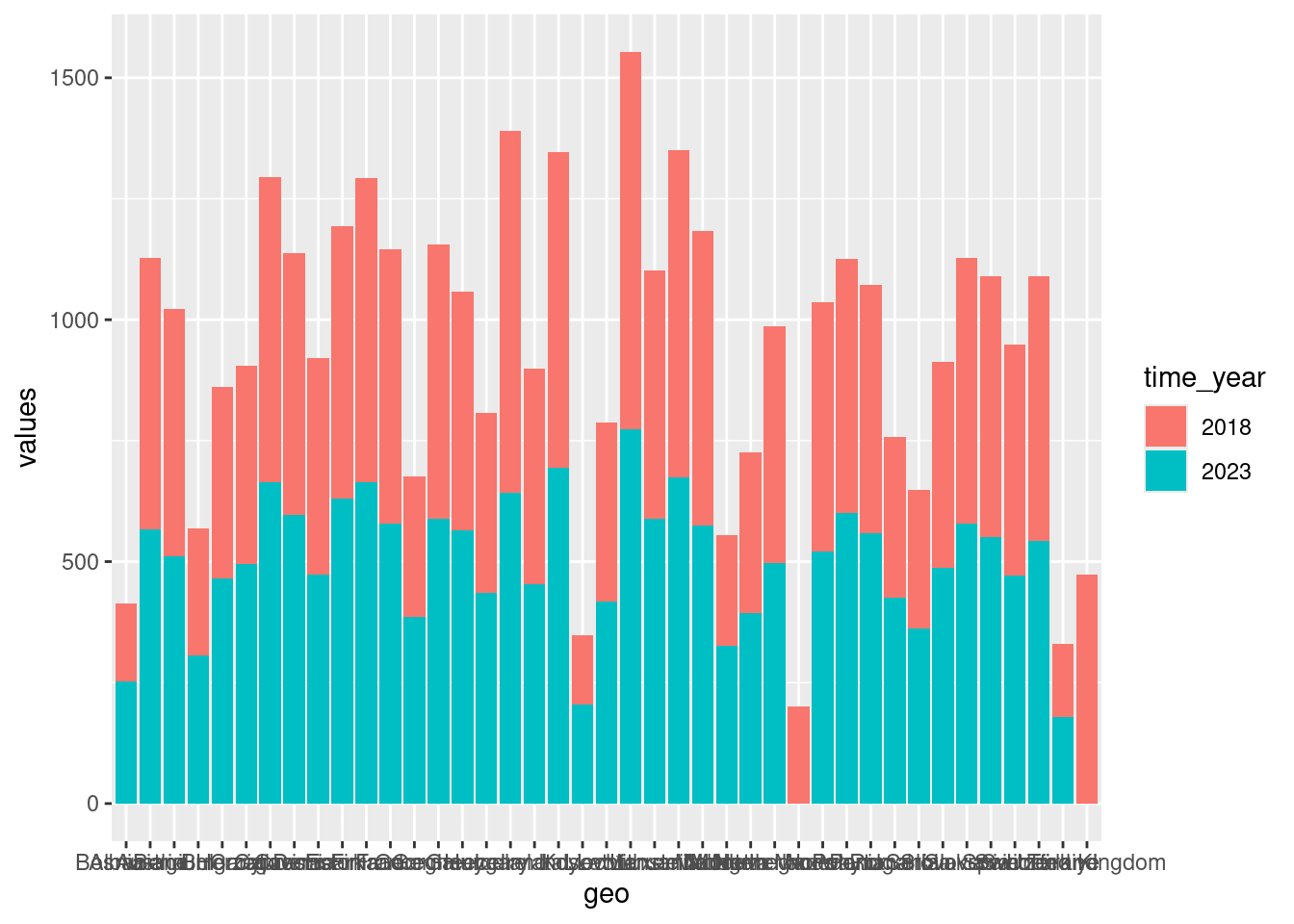
Es ist noch etwas Nacharbeit nötig. Sieht man in die Hilfe von geom_col(), dann kann man nachlesen, dass es standardmäßig ein Stapelbalkendiagramm darstellt (stacked bar plot ). Möchte man die Balken nebeneinander haben (dodged bar plot), muss man das explizit sagen.
ggplot(data = car_numbers, mapping = aes(x = geo, y = values, fill = time_year)) +
geom_col(position = position_dodge()) 
Die Ländernamen erscheinen (wie es Standard ist) horizontal. In unserem Fall überdecken sie sich aber und wir sollten sie vertikal schreiben. Dazu gibt es eine neue Funktion aus ggplot2, die wie alle anderen mit einem + angehängt wird. Sie heißt theme(). Der Parameter, der für die Gestaltung der \(x\)-Achse zuständig ist, heißt axis.text.x Die Funktion element_text mit der Einstellung angle = 90 dreht die einzelnen Länder um 90 Grad. Die Aufgabe der beiden anderen Parameter finden Sie im Rahmen der Aufgaben heraus.
ggplot(data = car_numbers, mapping = aes(x = geo, y = values, fill = time_year)) +
geom_col(position = position_dodge()) +
theme(axis.text.x = element_text(angle = 90, hjust = 1, vjust = 0.5))Warning: Removed 2 rows containing missing values or values outside the scale range
(`geom_col()`).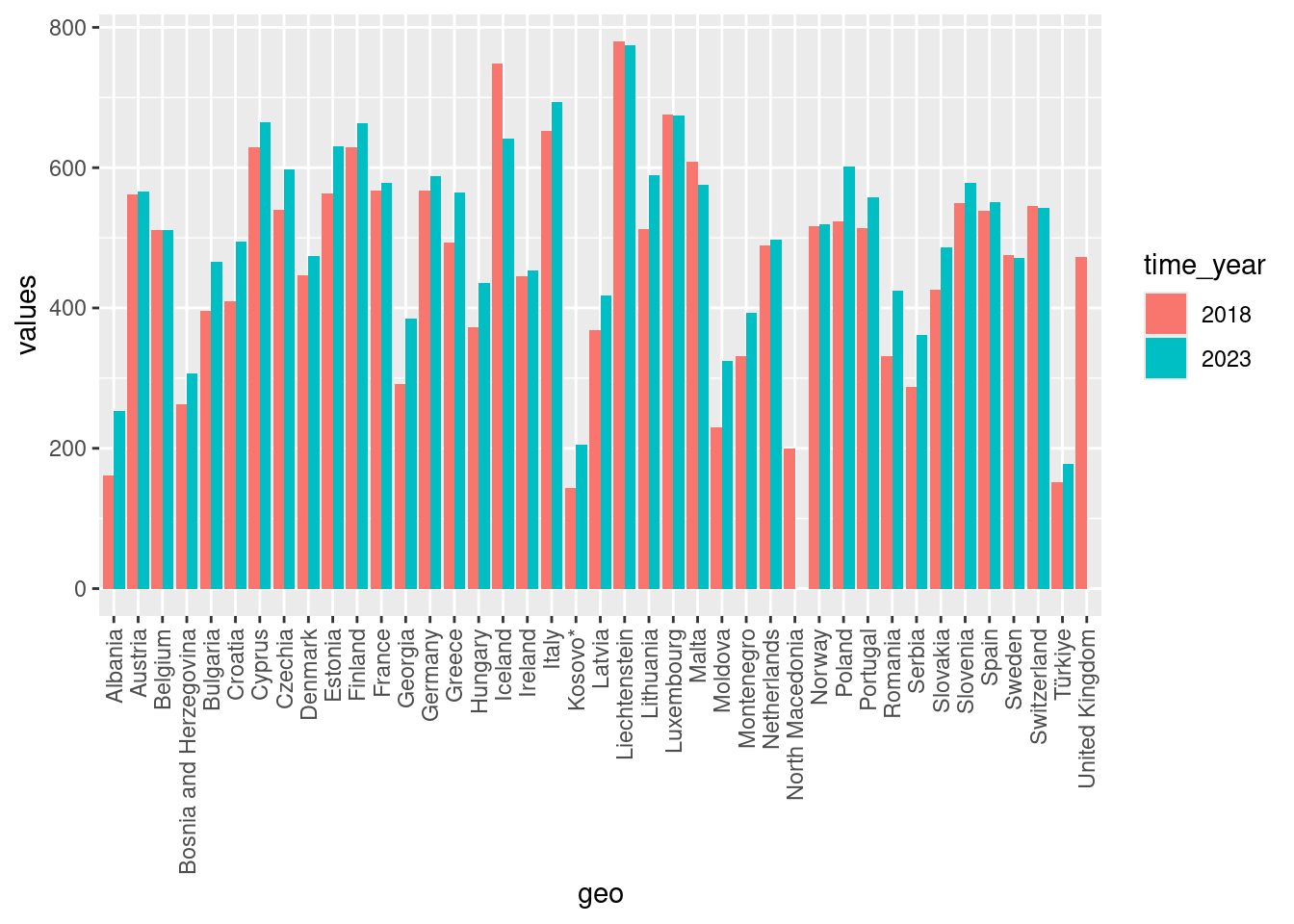
5.2 Lending Club – Peer-to-Peer-Kredite
Lending Club: Ein US-Unternehmen, das Individuen über eine Plattform ermöglicht, an andere Individuen Geld zu verleihen (Peer-to-Peer-Kredite). Wir haben den Datensatz bereits in der Vorlesung kennengelernt. Er ist in der Bibliothek openintro als loands_full_schema zu finden. Wir laden die Bibliothek und holen uns den Datensatz.
# Das R-Paket (auch Bibliothek genannt) laden
library(openintro)
# Datensatz laden
data(loans_full_schema)
# Datensatz ansehen
loans_full_schema5.2.1 Häufigkeitstabelle
Wir erstellen eine Häufigkeitstabelle der Variable homeownership. Dazu müssen wir die einzelnen Merkmalswerte auszählen lassen. Das übernimmt die Funktion count().
loans_full_schema %>%
count(homeownership)Die Tabelle sieht anders aus als in der Vorlesung. Das liegt daran, dass die Variable homeownership für die Vorlesung verändert wurde. Es ist nämlich störend, wenn die Merkmalsausprägungen mit Großbuchstaben geschrieben werden. Außerdem macht es logisch Sinn, zuerst die gemieteten, dann die mit einer Hypothek belegten und zum Schluss die Eigentumsobjekte zu sehen. Das spiegelt in einer gewissen Weise das Risiko wider, dass ein Kredit nicht bedient werden kann. Achtung: Es ist trotzdem keine ordinal-skalierte Variable!
Wir ändern die Darstellung der Variablen homeownership. Um den Originaldatensatz nicht zu überschreiben, erstellen wir einen neuen, den wir loans nennen.
loans <- loans_full_schema %>%
mutate(homeownership = tolower(homeownership),
homeownership = fct_relevel(homeownership, "rent", "mortgage", "own"))Sie sehen, dass man die beiden Änderungen in einem Aufruf zu mutate() durchführen darf. Zuerst macht die Funktion tolower() aus den Großbuchstaben Kleinbuchstaben, danach änder die Funktion fct_relevel() die Reihenfolge der Merkmalsausprägungen (levles). Jetzt entspricht das Ergebnis dem der Vorlesung.
loans %>%
count(homeownership)5.2.2 Kontingenztabelle
Eine Kontingenztabelle fasst zwei kategoriale Variablen zusammen. Jede Zeile zeigt die Anzahl der Kombinationen zwischen diesen Variablen.
loans %>%
count(application_type, homeownership)Die Tabelle sieht auch anders aus als in der Vorlesung. Sie ist nämlich tidy: jede Spalte ist eine Variable und jede Zeile ist eine Beobachtung. In diesem Fall möchte man es aber eigentlich untidy dargestellt haben. Das ist einer der seltenen Fälle, nämlich die Darstellung von Tabellen, wo das auch Sinn macht. Achtung, jetzt wird es nerdy 🤓.
Wir formatieren die Tabelle von lang tidy auf breit und untidy. Dabei wandern die Einträge der Spalte homeowndership in die Breite und werden zu neuen Spalten. Die einträge in den Tabellenzellen kommen aus der Spalte n.
loans %>%
count(application_type, homeownership) %>%
pivot_wider(names_from = homeownership, values_from = n)Jetzt fehlen nur noch die Zeilen- und Spaltensummen. Da hilft die Bibliothek janitor
library(janitor)
loans %>%
count(application_type, homeownership) %>%
pivot_wider(names_from = homeownership, values_from = n) %>%
adorn_totals(where = c("row", "col"))Bis auf wenige ästhetische Griffe ist das jetzt das Gleiche wie in der Vorlesung 😄.
5.3 Hausaufgaben
5.3.1 Grafik beschriften
Beschriften Sie die finale Grafik aus Kapitel 5.1.2 so, dass sie wie dort anfangs dargestellt aussieht.
5.3.2 Aufgaben der Funktion theme()
- Lesen Sie nach, was die Aufgabe der Funktion
theme()ist. Fassen Sie den Abschnitt Description kurz mit Ihren eigenen Worten zusammen. - Ich habe in der Vorlesung
theme_classic()benutzt. Ändern Sie die finale Grafik in Kapitel 5.1.2 so, dass auch dort diesesthemebenutzt wird. - Finden Sie heraus, was
hjustundvjusttun. Probieren Sie die Werte 0, 0.5 und 1 aus. Wie ändert sich die Position der Ländernamen?
5.3.3 Ihre Arbeit einreichen
Reichen Sie die Aufgabe aus Kapitel 5.3 bei FelloFish ein und erhalten Sie Feedback:
5.4 Exolorative Datenanalyse von kategorialen Daten vertiefen
Bearbeiten Sie das Kapitel 1 des Kurses “Exploratory Data Analysis in R” auf datacamp.