Kapitel 3 Datentypen in R
-
einen Datensatz aus einem Paket mit
data()laden - einen Datensatz explorieren
-
data.frame()undtibble()erstellen - Datensätze zusammenfassen
In diesem Kapitel geht es um eine kurze Exploration des Datensatzes gapminder und die Vorstellung von Datenobjekten und -typen in R.
Zuerst laden wir die notwendigen Pakete mithilfe der Funktion library() und geben den Paketnamen (ausnahmsweise) ohne Anführungszeichen an.
Man kann nur solche Pakete laden, die man bereits installiert hat. Um ein Paket zu installieren, nutzen wir die Funktion install.packages() und geben den Namen des Pakets in Anführungszeichen an.
install.packages('gapminder')3.1 Datenobjekte
Nun laden wir den Datensatz gapminder aus dem gleichnamigen Paket mithilfe der Funktion data(). Diese Funktion lädt Datensätze, die bereits in R base oder mit einem Paket installiert wurden.
data(gapminder)Um sich die Daten anzeigen zu lassen, geben wir den Namen des Datensatzes ein.
gapminder## # A tibble: 1,704 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # … with 1,694 more rowsDaten werden in R in Form von tabellenartigen Objekten abgelegt, sogen. data.frame oder tibble. Letztere sind die modernere Variante. Im Englischen würde man beides als dataframe bezeichnen.
Der Typ des Objekts steht oben, wenn man sich das Objekt anzeigen lässt. Im Fall des Objekts gapminder handelt es sich um ein tibble. Tibbles und Dataframes sind zweidimensional: erste Dimension sind die Zeilen, zweite die Spalten. Wir können die Anzahl der Zeilen und Spalten direkt in der ersten Zeile der Ausgabe ablesen: 1704 Zeilen und 6 Spalten. Alternativ kann man mit dem Befehl dim() die Größe des Objekts abfragen.
dim(gapminder)
3.2 Der $-Operator
In einem tibble oder data.frame stellen Spalten verschiedene Variablen dar. So ist etwa die erste Spalte country eine Variable, die Ländernamen enthält. In einer Zelle befindet sich jeweils ein Wert. In jeder Zeile stehen Einträge für verschiedene Variablen, die logisch zusammengehören: in der ersten Zeile befinden sich Daten zu Afghanistan, das in Asien liegt, aus dem Jahr 1952 zu Lebenserwartung, Bevölkerungsgröße und Bruttoinlandsprodukt pro Einwohner. Solche Datenstrukturen nennt man tidy. Spalten (i.e. Variablen) haben in der Regel Namen, und können mit diesen direkt angesprochen werden. Dazu benutzt man das Dollarzeichen, den $-Operator. Um z.B. die Variable country anzusprechen, tippen wir:
gapminder$countryEine einzelne Spalte eines tibble ist ein Vektor und wird nicht so schön dargestellt wie das Tibble selbst. Um nur die ersten 6 Zeilen zu sehen, kann man die Funktion head() benutzen.
head(gapminder$country)3.3 Datentypen
Die Datentypen der einzelnen Variablen sieht man in der zweiten Zeile der Ausgabe, wenn man sich das Tibble anzeigen lässt:
gapminder## # A tibble: 1,704 × 6
## country continent year lifeExp pop gdpPercap
## <fct> <fct> <int> <dbl> <int> <dbl>
## 1 Afghanistan Asia 1952 28.8 8425333 779.
## 2 Afghanistan Asia 1957 30.3 9240934 821.
## 3 Afghanistan Asia 1962 32.0 10267083 853.
## 4 Afghanistan Asia 1967 34.0 11537966 836.
## 5 Afghanistan Asia 1972 36.1 13079460 740.
## 6 Afghanistan Asia 1977 38.4 14880372 786.
## 7 Afghanistan Asia 1982 39.9 12881816 978.
## 8 Afghanistan Asia 1987 40.8 13867957 852.
## 9 Afghanistan Asia 1992 41.7 16317921 649.
## 10 Afghanistan Asia 1997 41.8 22227415 635.
## # … with 1,694 more rowsDie Variablen country und continent sind sogenannte Faktoren (abgekürzt mit <fct>). Es handelt sich hier um nominalskalierte Daten, i.e. eine endliche, abzählbare Anzahl von unterschiedlichen Messwerten ist möglich.
Alternativ können wir nach dem Datentypen mithilfe der Funktion class() fragen.
class(gapminder$country)## [1] "factor"Die einzelnen Werte eines factor kann man sich mit der Funktion levels() anzeigen lassen.
levels(gapminder$country)Die Variable year ist numerisch, beinhaltet aber nur ganze Zahlen und ist daher eine integer Variable (abgekürzt mit <int>).
class(gapminder$year)## [1] "integer"Die Variable lifeExp ist numerisch und verhältnisskaliert (abgekürzt mit <dbl> für double). Letzteres bedeutet, dass es für dies Variable einen absoluten Nullpunkt gibt, nämlich Lebenserwartung von null Jahren.
class(gapminder$lifeExp)## [1] "numeric"Um einen installierten Datensatz kennenzulernen, empfiehlt es sich, die Hilfeseiten dazu zu lesen.
?gapminder3.4 Kurze Exploration
Die Funktion summary() zeigt einen ersten Überblick über die Daten. Je nach Datentyp fasst diese Funktion die Daten unterschiedlich zusammen.
summary(gapminder)## country continent year lifeExp
## Afghanistan: 12 Africa :624 Min. :1952 Min. :23.60
## Albania : 12 Americas:300 1st Qu.:1966 1st Qu.:48.20
## Algeria : 12 Asia :396 Median :1980 Median :60.71
## Angola : 12 Europe :360 Mean :1980 Mean :59.47
## Argentina : 12 Oceania : 24 3rd Qu.:1993 3rd Qu.:70.85
## Australia : 12 Max. :2007 Max. :82.60
## (Other) :1632
## pop gdpPercap
## Min. :6.001e+04 Min. : 241.2
## 1st Qu.:2.794e+06 1st Qu.: 1202.1
## Median :7.024e+06 Median : 3531.8
## Mean :2.960e+07 Mean : 7215.3
## 3rd Qu.:1.959e+07 3rd Qu.: 9325.5
## Max. :1.319e+09 Max. :113523.1
## Alternativ kann man sich einen ersten Eindruck von den Daten mithilfe der Funktion glimpse() verschaffen. Sie zeigt die ersten paar Einträge des Datensatzes.
glimpse(gapminder)## Rows: 1,704
## Columns: 6
## $ country <fct> "Afghanistan", "Afghanistan", "Afghanistan", "Afghanistan", …
## $ continent <fct> Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, Asia, …
## $ year <int> 1952, 1957, 1962, 1967, 1972, 1977, 1982, 1987, 1992, 1997, …
## $ lifeExp <dbl> 28.801, 30.332, 31.997, 34.020, 36.088, 38.438, 39.854, 40.8…
## $ pop <int> 8425333, 9240934, 10267083, 11537966, 13079460, 14880372, 12…
## $ gdpPercap <dbl> 779.4453, 820.8530, 853.1007, 836.1971, 739.9811, 786.1134, …3.5 Visualisieren
Einen Plot des Datensatzes haben wir schon einmal erzeugt.
gapminder2007 <- gapminder %>%
filter(year == 2007)
ggplot(gapminder2007, aes(x = gdpPercap, y = lifeExp, color = continent, size = pop)) +
geom_point() +
scale_x_log10() +
xlab('GDP per capita') +
ylab('Life expectancy') +
labs(title = 'Gapminder data for the year 2007')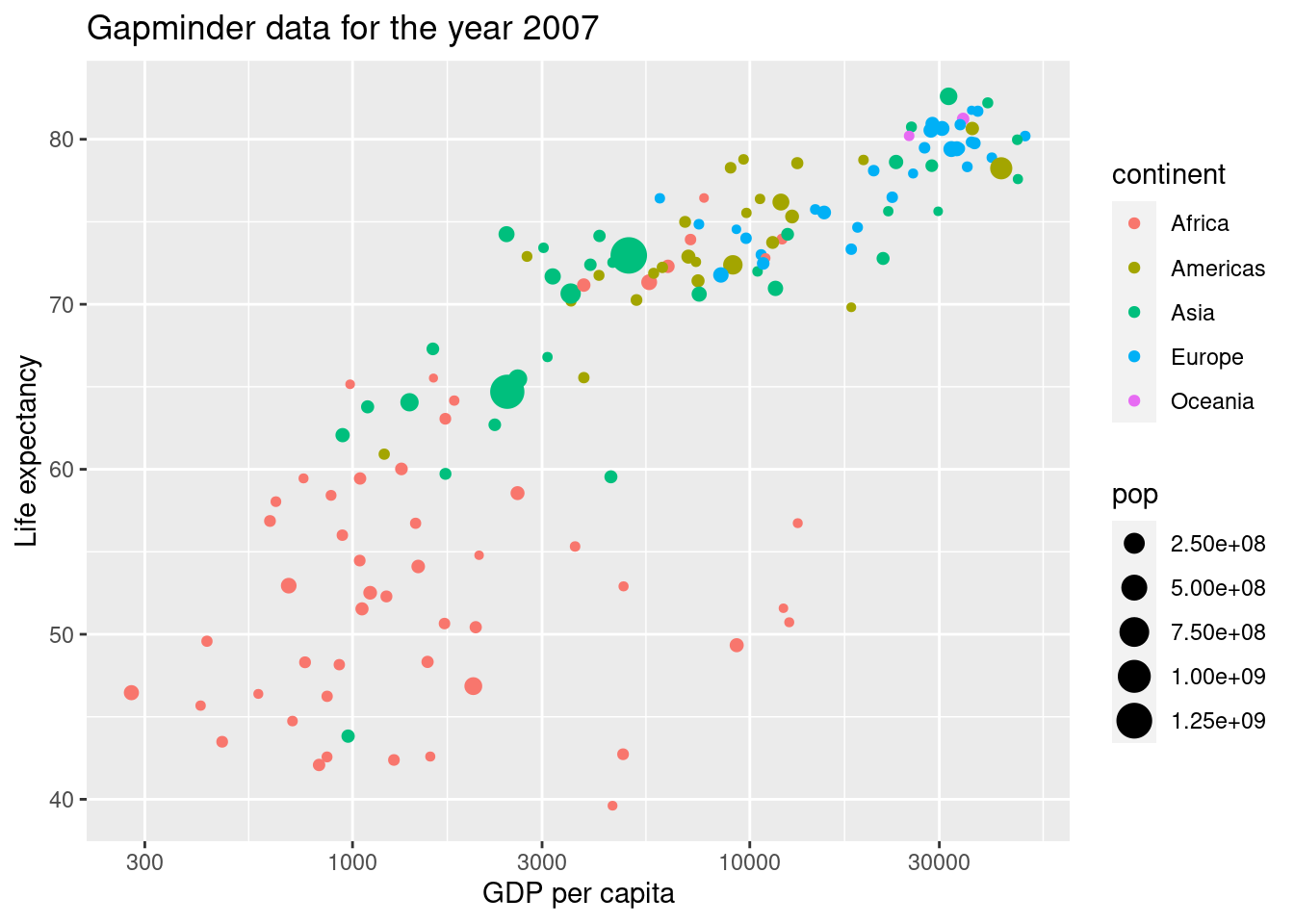
Die Variable year ist numerisch und kein factor. Daher kann man da keine Levels sehen. Wenn man aber trotzdem die einzelnen Jahre sich anzeigen lassen möchte, dann hilft die Funktion unique().
unique(gapminder$year)## [1] 1952 1957 1962 1967 1972 1977 1982 1987 1992 1997 2002 2007Wir sehen, dass es Einträge seit 1952 gibt. Wir verändern den Code so, dass das Jahr 1952 dargestellt wird.
gapminder1952 <- gapminder %>%
filter(year == 1952)
ggplot(gapminder1952, aes(x = gdpPercap, y = lifeExp, color = continent, size = pop)) +
geom_point() +
scale_x_log10() +
xlab('GDP per capita') +
ylab('Life expectancy') +
labs(title = 'Gapminder data for the year 1952')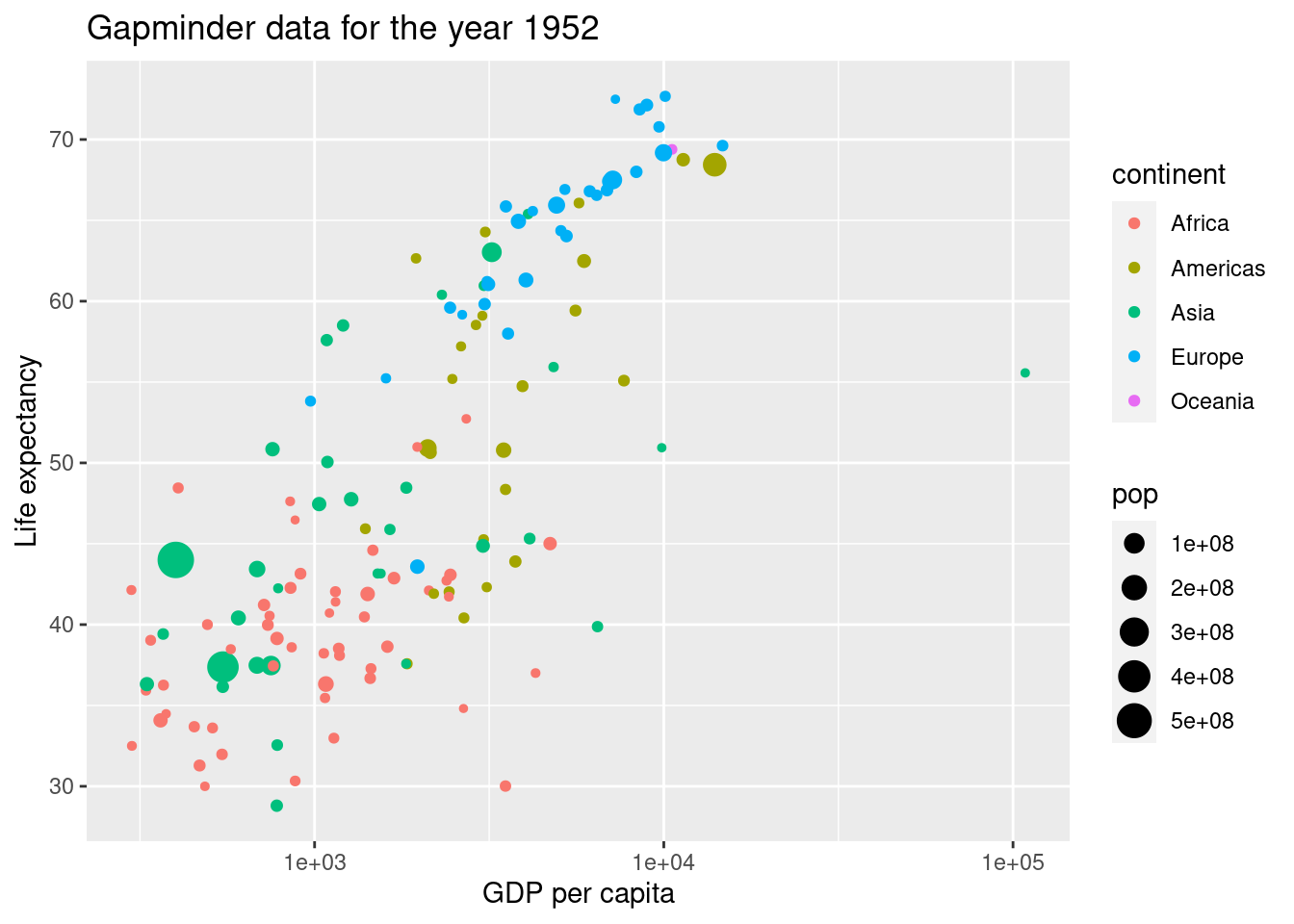
3.6 Lesestoff
r4ds, Kapitel 10 (Wickham and Grolemund 2021)
3.7 Aufgaben
3.7.1 Plot der Lebenserwartung
Stellen Sie statt der Variablen gdpPercap, die Bevölkerungsgröße pop auf der \(x\)-Achse dar. Wie verändern sich die Legenden? Die Skalierung der Symbole mit der Bevölkerungsgröße ist nicht sinnvoll. Verändern Sie die Skalierung zu Bruttoinlandsprodukt, indem Sie size = pop ersetzen mit size = gdpPercap.
3.7.2 Abflugdaten
Arbeiten Sie das Kapitel 1.4 Explore your first datasets in Ismay and Kim (2021) durch. Eventuell müssen Sie das Paket nycflights13 installieren.
3.7.3 Pinguine
Der Datensatz penguins aus dem Paket palmerpenguins eignet sich hervorragend zum Üben der Exploration. Die Website zum Datensatz erklärt, wie er entstanden ist.

Abbildung 3.1: Artwork by @allison_horst
Führen Sie eine ähnliche Exploration durch, wie wir sie für den Datensatz gapminder gemacht haben. Zum Visualisieren der Pinguine, nutzen Sie den folgenden Code:
ggplot(data = penguins,
mapping = aes(x = flipper_length_mm, y = body_mass_g, col = species)) +
geom_point() +
xlab('Flipper length (mm)') +
ylab('Body mass (g)')