Kapitel 6 Explorative Datenanalyse mit tidyverse
-
Kernpakete aus
tidyversebenennen -
ein einfaches Workflow (Daten einlesen, zusammenfassen, darstellen)
mit
tidyversedurchführen -
Funktionen des Pakets
dplyrfür Datentransformation anwenden
tidyverse ist eine Sammlung von R-Pakete, die explizit für Datenanalyse entwickelt wurden (https://www.tidyverse.org/). tidyverse versucht durch gemeinsame Philosophie in Design, Grammatik und Datenstruktur die Datenanalyse zu erleichtern (https://design.tidyverse.org/). Auch wenn tidyverse auf den ersten Blick etwas fremd erscheint, es ist ein Teil von R, kein eigenes Universum. Es ist also völlig in Ordnung, R-Basisfunktionen mit Funktionen aus tidyverse zu mischen.
Das wichtigste Einführungsbuch zu tidyverse ist sicherlich R4DS: “R for Data Science” (Wickham and Grolemund 2021), das Sie kostenlos online lesen können (https://r4ds.had.co.nz/).
6.1 Grundpakete
tidyverse enthält folgende Grundpakete, die alle installiert werden, wenn Sie install.packages('tidyverse') ausführen.
| Paketname | Kurzbeschreibung |
|---|---|
ggplot2 |
Visualisierung |
dplyr |
Datentransformation |
tidyr |
Datenbereinigung |
readr |
Daten einlesen |
purrr |
Funktionale Programmierung (Funktionen auf Objekte anwenden) |
tibble |
Erweiterung von data.frame
|
stringr |
Funktionen für Strings, d.h. Textvariablen |
forcats |
Funktionen für factor
|
Jedes dieser Pakete hat ein Cheat Sheet, eine übersichtliche Zusammenstellung der Funktionen des Pakets. Sie bekommen die Cheet Sheats über die tidyverse-Seite (https://www.tidyverse.org/packages/), indem Sie auf das jeweilige Paket klicken und zum Abschnitt ‘Cheatsheet’ scrollen.
6.2 Der explorative Workflow
6.2.1 Daten einlesen, revisited
Als Erstes laden wir die Bibliothek tidyverse.
Sie kennen bereits die Funktion read_delim() zum Einlesen von Textdateien. Die Funktion ist die allgemeinste Funktion der read_* Familie aus readr in tidyverse; read_csv() und read_csv2() sind jeweils für komma- und strichpunkt-getrennte Datensätze gedacht. In der Basisinstallation von R (also außerhalb von tidyverse) gibt die sehr umfangreiche Funktion read.table(), die ebenfalls zum Einlesen von Textdateien verwendet wird. Man könnte berechtigterweise fragen, warum neue Funktion (read_*) für etwas erfinden, was es schon gibt. Die Autoren von tidyverse versprechen Konsistenz und Geschwindigkeit. Ersteres war schon immer ein Problem von R, da es nicht von Computerspezialisten, sondern von Anwendern erfunden wurde. Daher ist eine Vereinheitlichung durch tidyverse mehr als willkommen. Und Geschwindigkeit ist spätestens bei größeren Datensätzen ein wichtiger Punkt.
Wir sehen uns Daten des Deutschen Wetterdienstes an, die ich am 24. Mai 2020 heruntergeladen habe (https://www.dwd.de/DE/leistungen/klimadatendeutschland/klimadatendeutschland.html). Auch das ist eine tolle Datenquelle für Berichte 😄. Der Datensatz enthält Stundenwerte für relative Luftfeuchte (%) und Lufttemperatur (°C) von drei Wetterstationen, nämlich Hof, Frankfurt und Köln-Bonn. Die Daten sind in der Datei Drei_Stationen.csv gespeichert.
Beim Einlesen zeigt Ihnen read_delim() bereits, welche Spalten und welche Datentypen es erkennt, mit trim_ws = T werden Leerzeichen aus Spalten entfernt.
temp_humid <- read_delim('data/Drei_Stationen.csv', delim = ';', trim_ws = T)## Rows: 39600 Columns: 6
## ── Column specification ────────────────────────────────────────────────────────
## Delimiter: ";"
## chr (1): eor
## dbl (5): STATIONS_ID, MESS_DATUM, QN_9, TT_TU, RF_TU
##
## ℹ Use `spec()` to retrieve the full column specification for this data.
## ℹ Specify the column types or set `show_col_types = FALSE` to quiet this message.Eine weitere Kontrolle bietet die Funktion print(), die das eingelesene Ergebnis übersichtlich (und im Notebook interaktiv) darstellt. Sie müssen hier nicht head() verwenden, da grundsätzlich nur die ersten 10 Zeilen dargestellt werden.
print(temp_humid)## # A tibble: 39,600 × 6
## STATIONS_ID MESS_DATUM QN_9 TT_TU RF_TU eor
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 2261 2018111900 3 -2.8 99 eor
## 2 2261 2018111901 3 -2.5 100 eor
## 3 2261 2018111902 3 -2.3 100 eor
## 4 2261 2018111903 3 -2 100 eor
## 5 2261 2018111904 3 -1.9 99 eor
## 6 2261 2018111905 3 -2.1 99 eor
## 7 2261 2018111906 3 -1.8 99 eor
## 8 2261 2018111907 3 -1.5 99 eor
## 9 2261 2018111908 3 -1.1 99 eor
## 10 2261 2018111909 3 -0.6 97 eor
## # … with 39,590 more rowsDas gleiche Ergebnis bekommen Sie auch ohne print(), wenn Sie wie gewohnt den Namen des Objekts tippen.
temp_humid## # A tibble: 39,600 × 6
## STATIONS_ID MESS_DATUM QN_9 TT_TU RF_TU eor
## <dbl> <dbl> <dbl> <dbl> <dbl> <chr>
## 1 2261 2018111900 3 -2.8 99 eor
## 2 2261 2018111901 3 -2.5 100 eor
## 3 2261 2018111902 3 -2.3 100 eor
## 4 2261 2018111903 3 -2 100 eor
## 5 2261 2018111904 3 -1.9 99 eor
## 6 2261 2018111905 3 -2.1 99 eor
## 7 2261 2018111906 3 -1.8 99 eor
## 8 2261 2018111907 3 -1.5 99 eor
## 9 2261 2018111908 3 -1.1 99 eor
## 10 2261 2018111909 3 -0.6 97 eor
## # … with 39,590 more rowsIn diesem Datensatz sind folgende Variablen (Spalten) enthalten (s. Datensatzbeschreibung des DWDs)
| Variablen | Beschreibung |
|---|---|
| STATIONS_ID | Stationsidentifikationsnummer |
| MESS_DATUM | Zeitstempel im Format yyyymmddhh |
| QN_9 | Qualitätsniveau der nachfolgenden Spalten |
| TT_TU | Lufttemperatur in 2m Höhe °C |
| RF_TU | relative Feuchte % |
| eor | Ende data record |
class(temp_humid)## [1] "spec_tbl_df" "tbl_df" "tbl" "data.frame"Das Objekt temp_humid ist ein tibble, ein data.frame mit “modernem” Verhalten. Z.B. gibt die Funktion print() nur die ersten 10 Zeilen aus, die Datentypen in den Spalten werden in hellgrau zwischen ‘<>’ mit angegeben etc. Mehr zu Tibbles finden Sie in Kapitel 10 “Tibbles” in R4DS.
6.3 Geschickter Umgang mit Zeit und Datum
Ein weiteres Paket, das zwar nicht zum Kern von tidyverse gehört, jedoch trotzdem extrem nützlich ist, heißt lubridate. Es hilft, Text sehr einfach in richtige Datums-Objekte zu transformieren (in Base-R muss man sich dafür kryptischen Datumsformate merken). Wir transformieren die Spalte temp_humid$MESS_DATUM in ein richtiges Datum mit Uhrzeit. Die Funktion ymd_h() kann character in ein richtiges Datumsformat transformieren, wenn das Datum als year, month, day, hour codiert ist. Es gibt noch weitere Varianten der Codierung, die Sie bei Bedarf in der Hilfe nachschlagen sollten.
## # A tibble: 39,600 × 6
## STATIONS_ID MESS_DATUM QN_9 TT_TU RF_TU eor
## <dbl> <dttm> <dbl> <dbl> <dbl> <chr>
## 1 2261 2018-11-19 00:00:00 3 -2.8 99 eor
## 2 2261 2018-11-19 01:00:00 3 -2.5 100 eor
## 3 2261 2018-11-19 02:00:00 3 -2.3 100 eor
## 4 2261 2018-11-19 03:00:00 3 -2 100 eor
## 5 2261 2018-11-19 04:00:00 3 -1.9 99 eor
## 6 2261 2018-11-19 05:00:00 3 -2.1 99 eor
## 7 2261 2018-11-19 06:00:00 3 -1.8 99 eor
## 8 2261 2018-11-19 07:00:00 3 -1.5 99 eor
## 9 2261 2018-11-19 08:00:00 3 -1.1 99 eor
## 10 2261 2018-11-19 09:00:00 3 -0.6 97 eor
## # … with 39,590 more rows6.3.1 Daten zusammenfassen
Die drei Wetterstationen haben folgende IDs:
station_ids <- c('2261' = 'Hof', '1420' = 'Frankfurt', '2667' = 'Koeln')Wir zählen nach, wie viele Messpunkte es pro Station gibt. Dazu müssen wir den Datensatz nach der Variablen STATION_ID gruppieren und dann pro Gruppe die Anzahl der Datenpunkte ermitteln:
## # A tibble: 3 × 2
## # Groups: STATIONS_ID [3]
## STATIONS_ID n
## <dbl> <int>
## 1 1420 13200
## 2 2261 13200
## 3 2667 13200Die Zeichenkombination %>% heißt Pipe-Operator (pipe) und wird als ‘und dann’ gelesen (then). Der Ausdruck temp_humid %>% group_by(STATIONS_ID) %>% count() heißt also: nimm das Objekt temp_humid, gruppiere es nach der Variablen STATION_ID und dann zähle die Einträge pro Gruppe zusammen. Der Pipe-Operator ist die Kernphilosophie von tidyverse und wird Ihnen überall begegnen. Der Operator stammt aus dem Paket magrittr (https://magrittr.tidyverse.org/). Seine Hauptaufgabe ist es, den Code übersichtlicher und besser lesbar zu machen (vielleicht nicht gleich zu Beginn der Lernkurve, aber schon bald 😎).
6.4 Die Grammatik der Datenmanipulation – dplyr
Die Funktion count() gehört zum Paket dplyr, das für Datentransformationen zuständig ist. Es ist mal wieder eine Grammatik. Dieses Paket enthält 5 Grundfunktionen (alle nach Verben benannt, damit man gleich weiß, was frau tut 😄):
| Funktion | Bedeutung |
|---|---|
filter() |
Wähle Daten anhand ihrer Werte |
arrange() |
Sortiere Zeilen |
select() |
Wähle Variablen anhand ihrer Namen |
mutate() |
Erstelle neue Variablen als Funktionen vorhandener Variablen |
summarize() |
Fasse Daten zusammen |
Wir möchten nur von einer bestimmten Station die Anzahl der Messwerte wissen möchten, dann filtern wir vorher.
## # A tibble: 1 × 1
## n
## <int>
## 1 13200Beim Filtern läuft eine logische Abfrage. D.h. es wird bei jeden Eintrag in STATION_ID nachgesehen, ob da der Wert 2667 steht. Wenn da 2667 steht, dann gibt == ein TRUE zurück, wenn da etwas anderes steht, dann gibt == ein FALSE zurück. Und die Funktion filter() behält nur die Zeilen, bei denen == ein TRUE zurückgegeben hat.
Weiter wichtige logische und relationale Operatoren finden Sie hier in der Hilfe zu filter(). Hier ein paar einfache Beispiele
| Operator | Bedeutung |
|---|---|
==/ > / >=
|
ist die linke Seite gleich / größer / größer-gleich als die rechte Seite |
!= |
ist die linke Seite ungleich der rechten Seite |
Zudem kann man bei filter() die Anfragen auch kombinieren. Wir wollen z.B. die Stationen Köln und Hof haben. | ist der logische Operator oder. Wenn man also sowohl Köln als auch Hof haben will, sagt man: finde alles, was entweder gleich Köln oder gleich Hof ist.
temp_humid %>%
filter(STATIONS_ID == '2667' | STATIONS_ID == '2261') %>%
group_by(STATIONS_ID) %>%
count()## # A tibble: 2 × 2
## # Groups: STATIONS_ID [2]
## STATIONS_ID n
## <dbl> <int>
## 1 2261 13200
## 2 2667 13200Das Gleiche erreicht man mit folgendem Code, indem man Frankfurt ausschließt:
## # A tibble: 2 × 2
## # Groups: STATIONS_ID [2]
## STATIONS_ID n
## <dbl> <int>
## 1 2261 13200
## 2 2667 13200Alternative kann man auch den Operator %in% verwenden. Dieser ist sehr nützlich, wenn man anhand einer einzelnen Variablen filtert, aber unterschiedliche Einträge auswählen möchte (z.B. zwei Messstationen). Es wird bei jeder Zeile in der Variablen STATIONS_ID nun überprüft, ob hier entweder 2667 oder 2261 stehen.
## # A tibble: 2 × 2
## # Groups: STATIONS_ID [2]
## STATIONS_ID n
## <dbl> <int>
## 1 2261 13200
## 2 2667 132006.4.1 Daten plotten
Wir sehen uns die Daten erst mal an, bevor wir weiter machen. Wir plotten die Temperatur. Weil es sich um Zeitreihen handelt, möchten wir sie eher untereinander als nebeneinander haben. Daher setzen wir bei facet_wrap() den Parameter nrow = 3.
ggplot(data = temp_humid, aes(x = MESS_DATUM, y = TT_TU)) +
geom_line() +
facet_wrap(~STATIONS_ID, nrow = 3) +
labs(x = 'Zeit', y = 'Temperatur (°C)')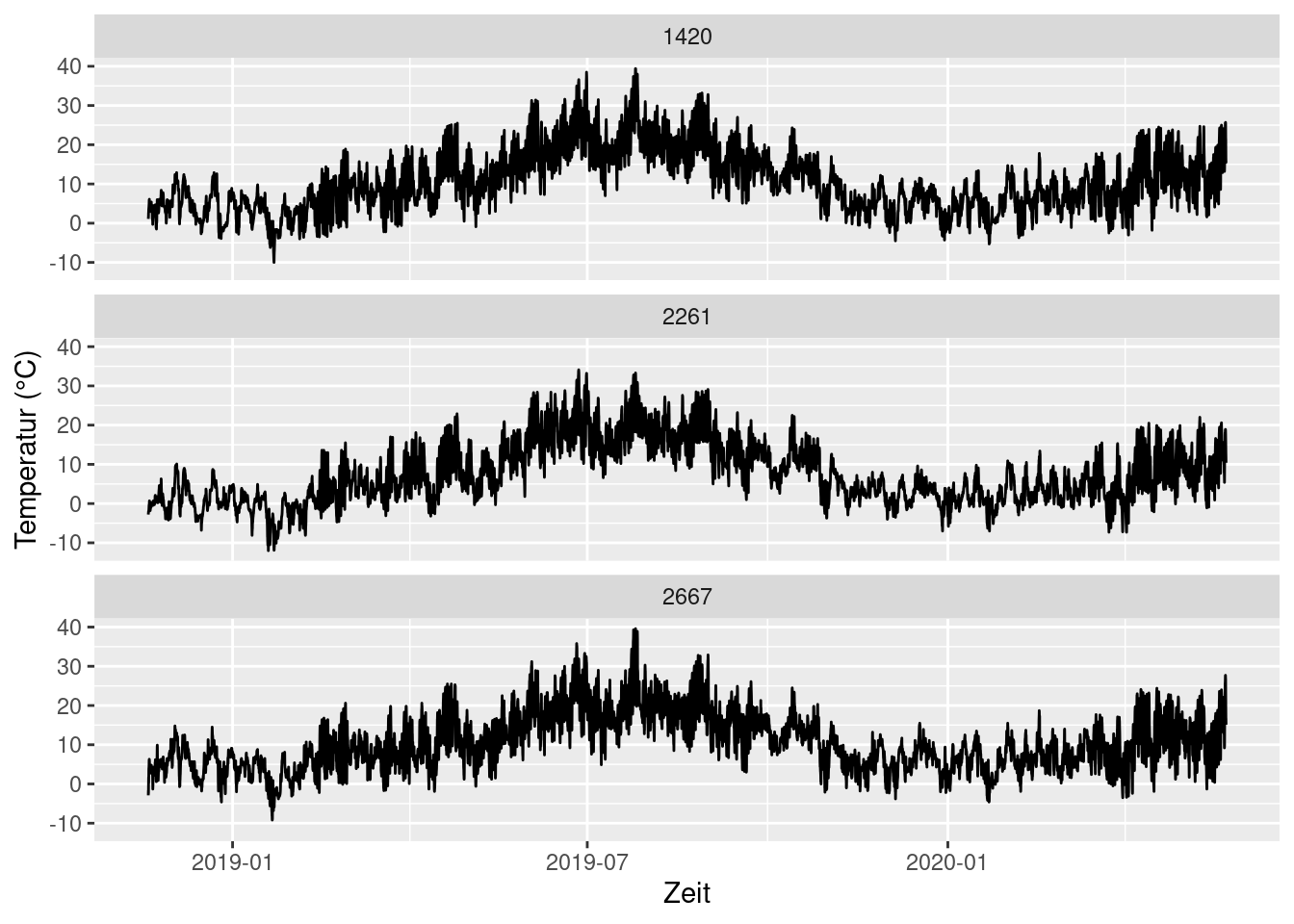
6.4.2 Neue Variablen erstellen mit mutate()
Wir wollen die Monatsmittelwerte und die Standardabweichungen für die Temperatur berechnen und diese darstellen. Als Erstes erstellen wir zwei neue Spalten, die jeweils das Jahr und den Monat beinhalten. Die beiden neuen Spalten werden am Ende von temp_humid angehängt. Um neue Spalten zu erstellen, nutzen wir die Funktion mutate(). Die Funktionen year()und month() gehören zur Bibliothek lubridate und extrahieren jeweils das Jahr und den Monat aus MESS_DATUM.
## # A tibble: 39,600 × 8
## STATIONS_ID MESS_DATUM QN_9 TT_TU RF_TU eor year month
## <dbl> <dttm> <dbl> <dbl> <dbl> <chr> <dbl> <dbl>
## 1 2261 2018-11-19 00:00:00 3 -2.8 99 eor 2018 11
## 2 2261 2018-11-19 01:00:00 3 -2.5 100 eor 2018 11
## 3 2261 2018-11-19 02:00:00 3 -2.3 100 eor 2018 11
## 4 2261 2018-11-19 03:00:00 3 -2 100 eor 2018 11
## 5 2261 2018-11-19 04:00:00 3 -1.9 99 eor 2018 11
## 6 2261 2018-11-19 05:00:00 3 -2.1 99 eor 2018 11
## 7 2261 2018-11-19 06:00:00 3 -1.8 99 eor 2018 11
## 8 2261 2018-11-19 07:00:00 3 -1.5 99 eor 2018 11
## 9 2261 2018-11-19 08:00:00 3 -1.1 99 eor 2018 11
## 10 2261 2018-11-19 09:00:00 3 -0.6 97 eor 2018 11
## # … with 39,590 more rowsJetzt können wir einen neuen Datensatz mit den Mittelwerten erstellen. Dafür gruppieren wir erst einmal die Daten nach STATIONS_ID, year und month. Die Mittelwerte sollen ja je Station, Jahr und Monat berechnet werden. Beim Gruppieren gibt man die Variablen ohne Anführungszeichen und ohne einen Vektor zu bilden, einfach durch Kommas getrennt an.
monthly_means <- temp_humid %>%
group_by(STATIONS_ID, year, month) %>%
summarize(mean_T = mean(TT_TU), mean_RH = mean(RF_TU),
sd_T = sd(TT_TU), sd_RH = sd(RF_TU))## `summarise()` has grouped output by 'STATIONS_ID', 'year'. You can override
## using the `.groups` argument.
monthly_means## # A tibble: 57 × 7
## # Groups: STATIONS_ID, year [9]
## STATIONS_ID year month mean_T mean_RH sd_T sd_RH
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl>
## 1 1420 2018 11 4.00 79.7 1.82 9.96
## 2 1420 2018 12 4.73 83.7 4.20 11.7
## 3 1420 2019 1 2.12 79.3 3.76 10.0
## 4 1420 2019 2 4.48 74.1 4.69 17.7
## 5 1420 2019 3 8.28 68.5 4.08 16.1
## 6 1420 2019 4 11.7 61.0 5.52 21.8
## 7 1420 2019 5 12.7 67.5 4.64 20.1
## 8 1420 2019 6 21.4 60.6 6.05 21.2
## 9 1420 2019 7 21.6 55.6 5.90 21.8
## 10 1420 2019 8 20.7 65.6 4.94 20.8
## # … with 47 more rowsDie Struktur von monthly_means zeigt uns, dass es sich um gruppierte Daten handelt.
str(monthly_means)## grouped_df [57 × 7] (S3: grouped_df/tbl_df/tbl/data.frame)
## $ STATIONS_ID: num [1:57] 1420 1420 1420 1420 1420 1420 1420 1420 1420 1420 ...
## $ year : num [1:57] 2018 2018 2019 2019 2019 ...
## $ month : num [1:57] 11 12 1 2 3 4 5 6 7 8 ...
## $ mean_T : num [1:57] 4 4.73 2.12 4.48 8.28 ...
## $ mean_RH : num [1:57] 79.7 83.7 79.3 74.1 68.5 ...
## $ sd_T : num [1:57] 1.82 4.2 3.76 4.69 4.08 ...
## $ sd_RH : num [1:57] 9.96 11.68 10.04 17.73 16.1 ...
## - attr(*, "groups")= tibble [9 × 3] (S3: tbl_df/tbl/data.frame)
## ..$ STATIONS_ID: num [1:9] 1420 1420 1420 2261 2261 ...
## ..$ year : num [1:9] 2018 2019 2020 2018 2019 ...
## ..$ .rows : list<int> [1:9]
## .. ..$ : int [1:2] 1 2
## .. ..$ : int [1:12] 3 4 5 6 7 8 9 10 11 12 ...
## .. ..$ : int [1:5] 15 16 17 18 19
## .. ..$ : int [1:2] 20 21
## .. ..$ : int [1:12] 22 23 24 25 26 27 28 29 30 31 ...
## .. ..$ : int [1:5] 34 35 36 37 38
## .. ..$ : int [1:2] 39 40
## .. ..$ : int [1:12] 41 42 43 44 45 46 47 48 49 50 ...
## .. ..$ : int [1:5] 53 54 55 56 57
## .. ..@ ptype: int(0)
## ..- attr(*, ".drop")= logi TRUEDa wir aber mit den Daten weiter rechnen wollen, ist es besser, die Gruppierung wieder aufzugeben. Es könnte sonst später Fehlermeldungen geben.
monthly_means <- ungroup(monthly_means)Um die Daten als Zeitreihen zu plotten, erstellen wir noch eine ordentliche Zeit-Spalte. Die Funktion parse_date_time() kann aus character richtige Datums-Zeitobjekte erstellen. Sie ist allgemeiner als die oben verwendete ymd_h() Funktion, da man hier das Format explizit angeben kann. In unserem Fall ist das Format ‘ym’ für Jahr und Monat.
monthly_means <- monthly_means %>%
mutate(year_month = parse_date_time(paste0(year, month), orders = 'ym', tz = 'CET'))
monthly_means## # A tibble: 57 × 8
## STATIONS_ID year month mean_T mean_RH sd_T sd_RH year_month
## <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dbl> <dttm>
## 1 1420 2018 11 4.00 79.7 1.82 9.96 2018-11-01 00:00:00
## 2 1420 2018 12 4.73 83.7 4.20 11.7 2018-12-01 00:00:00
## 3 1420 2019 1 2.12 79.3 3.76 10.0 2019-01-01 00:00:00
## 4 1420 2019 2 4.48 74.1 4.69 17.7 2019-02-01 00:00:00
## 5 1420 2019 3 8.28 68.5 4.08 16.1 2019-03-01 00:00:00
## 6 1420 2019 4 11.7 61.0 5.52 21.8 2019-04-01 00:00:00
## 7 1420 2019 5 12.7 67.5 4.64 20.1 2019-05-01 00:00:00
## 8 1420 2019 6 21.4 60.6 6.05 21.2 2019-06-01 00:00:00
## 9 1420 2019 7 21.6 55.6 5.90 21.8 2019-07-01 00:00:00
## 10 1420 2019 8 20.7 65.6 4.94 20.8 2019-08-01 00:00:00
## # … with 47 more rowsDer Code paste0(year, month) “klebt” die Daten in der Variablen year und month zusammen. Das ist nötig, da die Funktion parse_date_time() einen Charaktervektor als Input erwartet und keine zwei getrennten Spalten. Da das Datum außer dem Jahr und dem Monat noch einen Tag braucht, hat parse_date_time() den Ersten eines jeden Monats genommen.
ggplot(data = monthly_means, aes(x = year_month, y = mean_T, col = factor(STATIONS_ID))) +
geom_line() +
labs(x = 'Zeit', y = 'Temperatur (°C)', color = 'Messstation')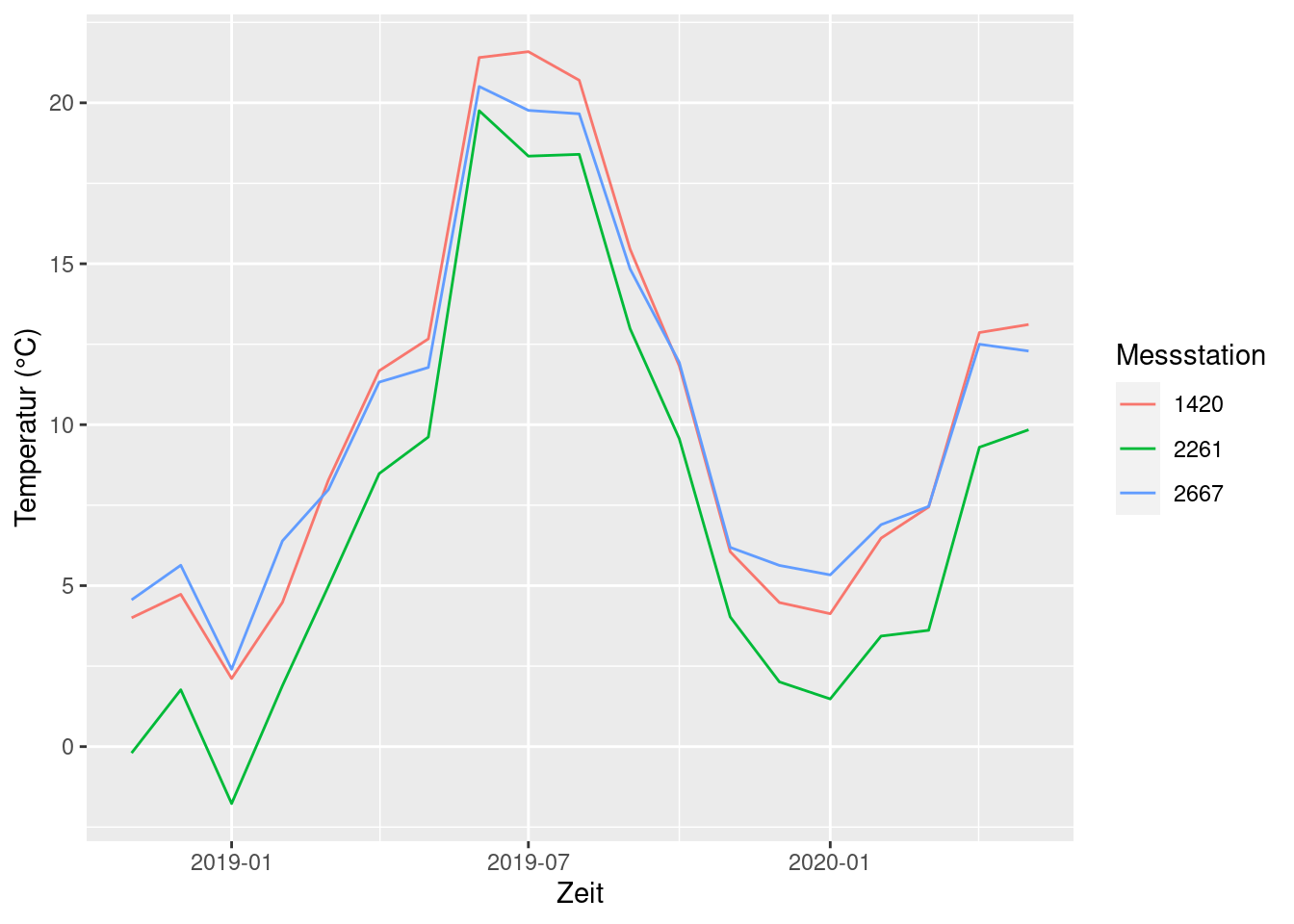
Alternativ können wir die Mittelwerte mit den Standardabweichungen darstellen.
ggplot(monthly_means, aes(x = year_month, y = mean_T, ymin = mean_T - sd_T, ymax = mean_T + sd_T)) +
geom_errorbar() +
geom_point() +
facet_wrap(~STATIONS_ID, nrow = 3) +
labs(x = 'Zeti', y = 'Temperatur (°C)')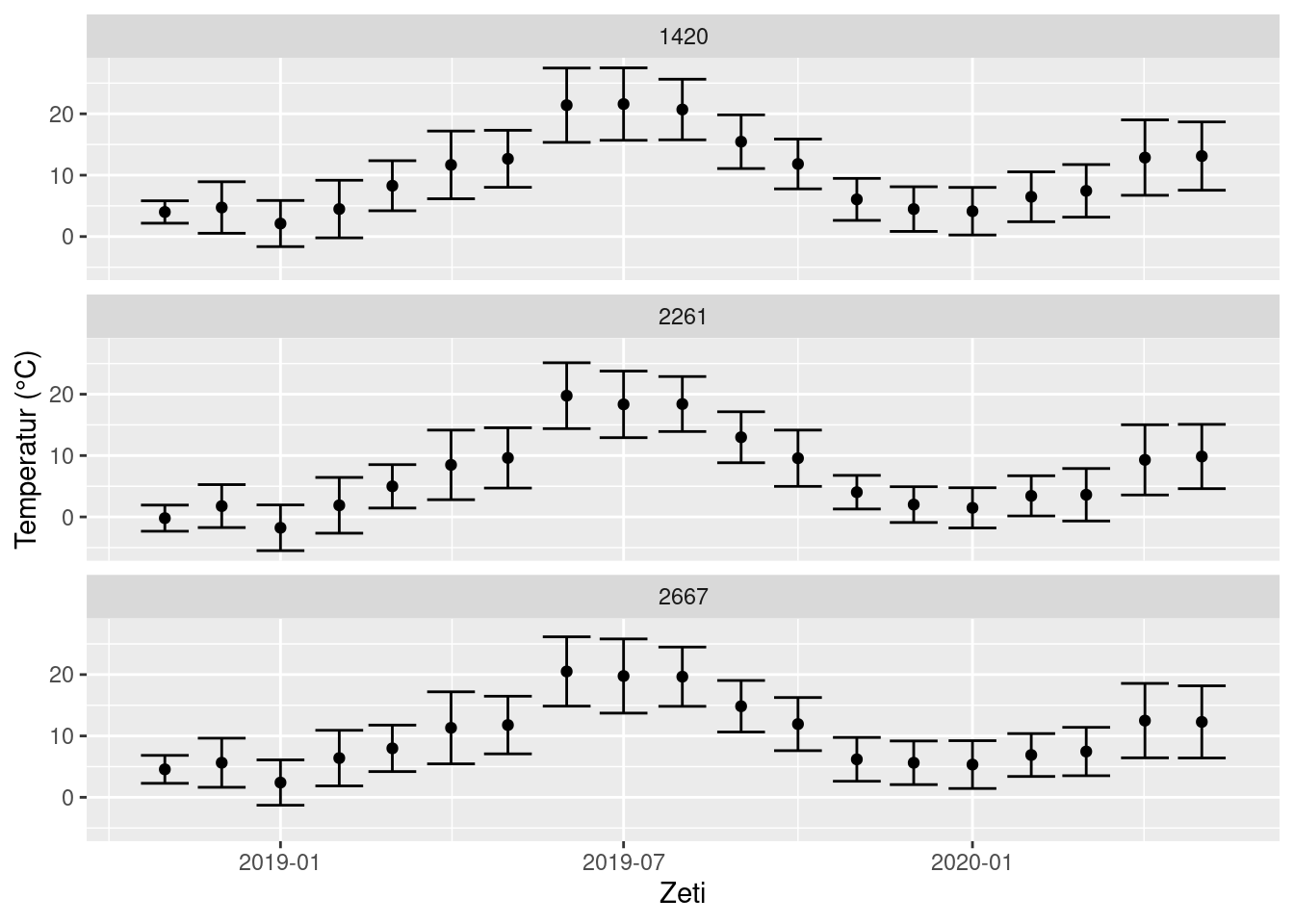
Oder, weil es gerade Spaß macht, als halb-transparentes Band. Ich hoffe, Sie haben jetzt Lust, das Kapitel 5 im ggplot2 Buch zu lesen 😎.
ggplot(monthly_means, aes(x = year_month, y = mean_T, ymin = mean_T - sd_T, ymax = mean_T + sd_T)) +
geom_ribbon(alpha = 0.5) +
geom_line() +
facet_wrap(~STATIONS_ID, nrow = 3) +
labs(x = 'Zeit', y = 'Temperatur (°C)')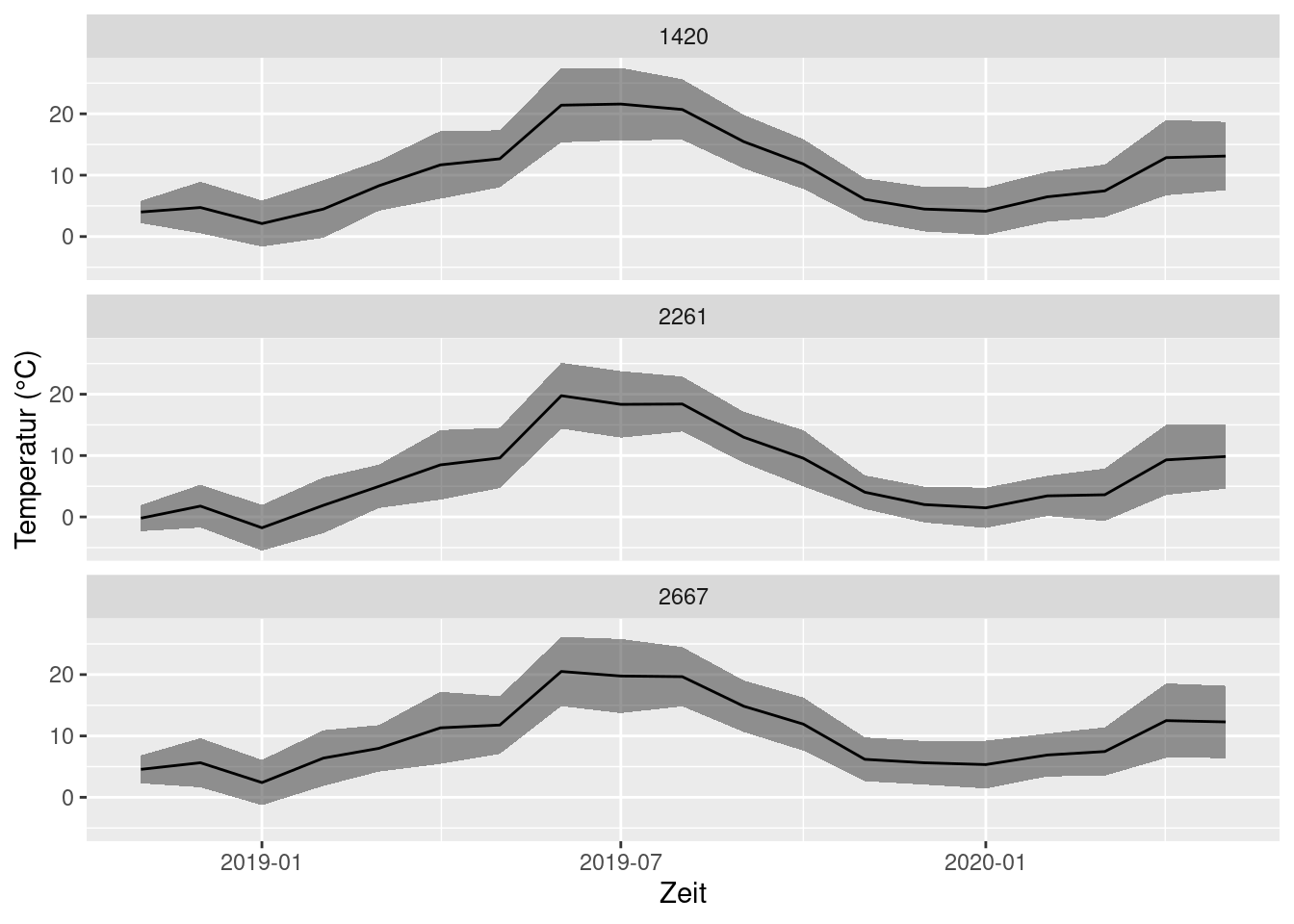
Ein letzter Trick. Die Überschriften für die Teilgrafiken sind ungeschickt, da man die IDs als Mensch einfach nicht zuordnen kann. Weiter oben haben wir einen benannten Vektor definiert, der die Klarnamen enthält.
station_ids## 2261 1420 2667
## "Hof" "Frankfurt" "Koeln"Diesen Vektor nutzen wir als Titel.
ggplot(monthly_means, aes(x = year_month, y = mean_T, ymin = mean_T - sd_T, ymax = mean_T + sd_T)) +
geom_ribbon(alpha = 0.5) +
geom_line() +
facet_wrap(~STATIONS_ID, nrow = 3, labeller = labeller(STATIONS_ID = station_ids)) +
labs(x = 'Zeit', y = 'Temperatur (°C)')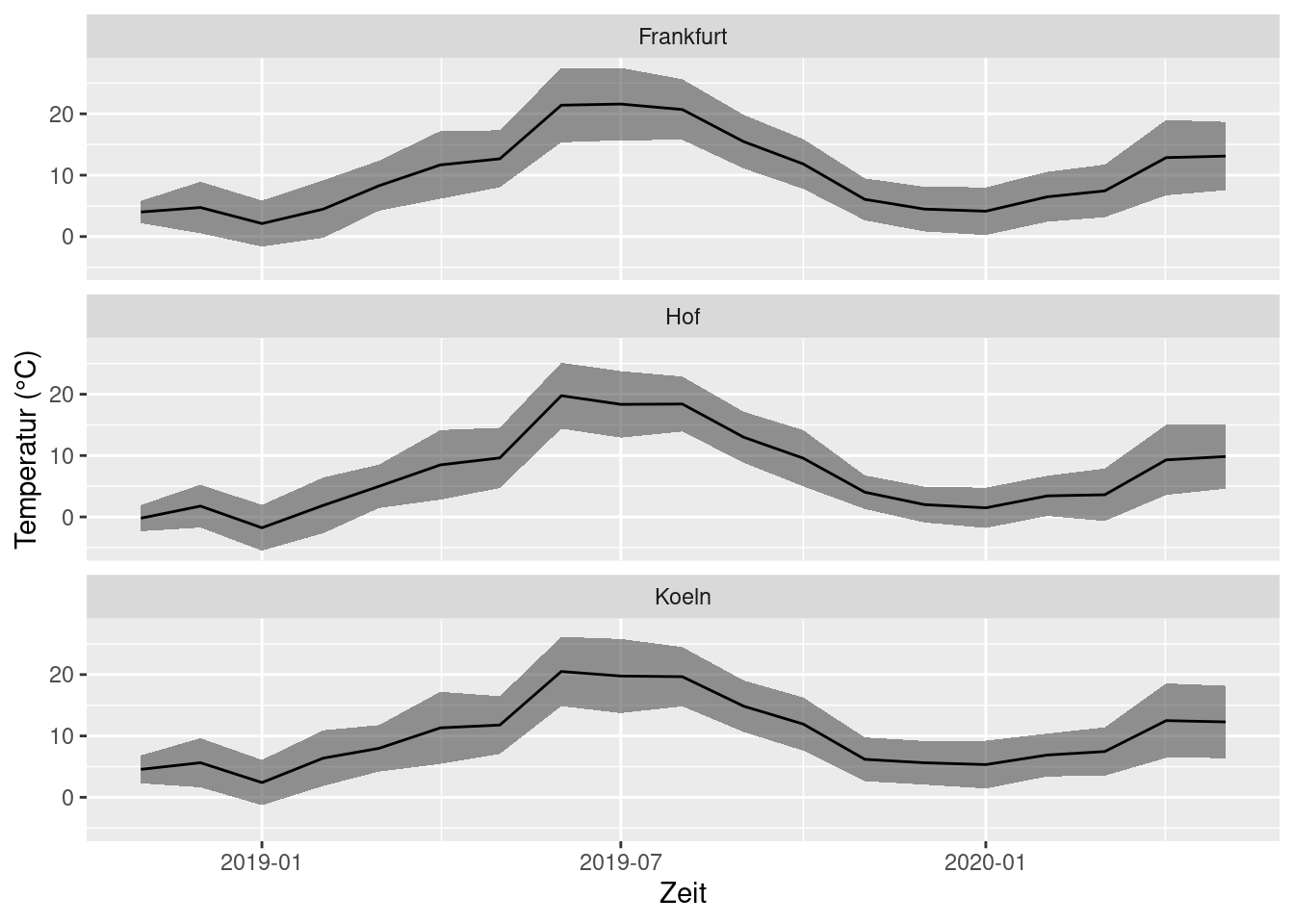
6.5 Lesestoff
Kapitel 3 in Ismay and Kim (2021)
6.6 Weiterführende Literatur und Videos
R4DS Wickham and Grolemund (2021): Kapitel 5 “Data transformation”
Eine live Analyse des Hauptautors von
tidyverse, Hadley Wickham. Empfehlenswert, auch wenn er viel zu schnell tippt 😄.